Active Directory backup is one of those areas where boring is usually good. Domain controllers have replication metadata, invocation IDs, USNs, SYSVOL content, and service state that need to remain consistent, so system state backups and tested forest-recovery procedures are still the safest foundation.
2026 context: the core advice still holds: for domain controllers, prefer backup and restore methods that are AD-aware and supported by Microsoft. Modern hypervisors and cloud platforms can reduce some historical USN rollback risk through VM-Generation ID support, but that is not the same thing as a complete, tested Active Directory disaster recovery plan.
When virtual infrastructure first started becoming popular ‘snapshots’ seemed like they might be logical choice as a DR approach, but they were kryptonite for a healthy directory service. Likewise for ‘cloning’ also a bad choice at the time. And now with IaaS hosted VM’s picking up momentum the temptation to use the platform snapshot functionality, cloning or other interesting techniques might be creeping back in.
This post covers the main reasons that alternate backup strategies might not be the right thing to do in most environments.
The two key components/operations of the active directory service that can land you in trouble are with backup and restore are:
- Update Sequence Numbers (USN’s)
- Domain Controller Invocation ID’s.
USN’s:
Update sequence numbers are assigned to every change (or set of changes) that happen on a domain controller. That could be a change of a persons name, when you add a new domain controller, when the directory service is doing clever things to build replication topology for you under the covers or even when a security descriptor is modified. Everything will be assigned a USN.
USN’s are assigned by the domain controller on which the change occurs, and the USN to be assigned might be in a completely different range depending on which domain controller makes the change.
You might see big variation between a brand new domain controller and one you’ve had in the environment for a long time for example.
You can inspect USN’s plenty of ways, but I like looking at the metadata via repadmin:
repadmin /showobjmeta localhost "cn=chad,cn=users,dc=dropbearsec,dc=com"
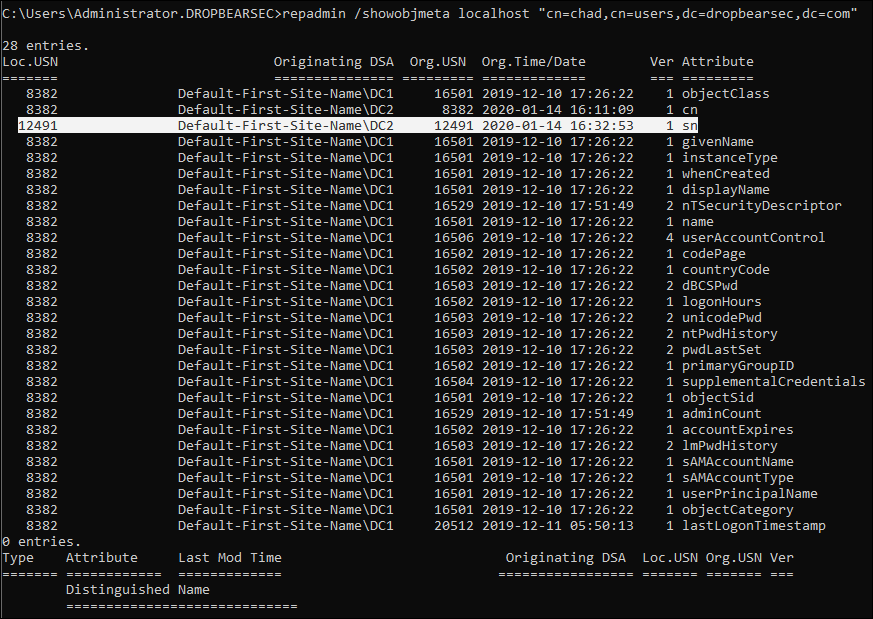
In the example above you can see that when i updated the surname attribute of this object, the local USN on the domain controller processing the change (DC2) was 12491. (From a security context we can also see when the change was made and we could go inspect the event logs on that domain controller to learn more. But that’s not important right now).
The second point is the way replication works (at a high level) for AD: Domain controllers pull changes.
So, the next time DC1 wants to replicate with DC2 it will say: “Give me everything that happened since your Update Sequence Number (USN) 12491…. (called the “high watermark value”).
Now, consider what might happen if we took a snapshot, completely independent of the directory service using AWS or whatever service you are hosting on & then we recovered the domain controller using that snapshot 6 months from now
- When the replication window opens, DC1 is going to be asking DC2 for changes that happened since the last sync (before the snapshot was used to recover the domain controller).
- We can assume that the number is something much larger than 12491 since lots of changes will have happened on this domain controller in the meantime. Lets say its only 12591; that is, 100 changes have happened since the original snapshot was made (it will probably be an order of magnitude more).
- DC2, restored from snapshot appears healthy and will probably process changes like a good domain controller. But do remember that DC2’s local USN table is back at 12491 because we restored from a snapshot.
- 100 new changes happen on DC2 but unexpected behaviors start to appear in the environment. Maybe someone who was married and chose to change their name has it appear differently at different times; maybe logins fail due to wrong password or computers say “unable to establish secure channel”…. The changes after this 100 replicate as usual and the directory appears normal.
- Remember, Domain Controllers pull changes. As far as DC1 is concerned it will only ever ask for USN 12591 and above. The 100 changes won’t replicate to any other domain controllers.
- It is called USN Rollback, and it is going to hurt.
It is important to mention at this point that I’m being a little dramatic. Microsoft ‘fixed’ this as best they could a while back and the fix is in all currently supported versions of Windows Server. But let me go a step further and say that the symptoms mentioned in the 4th bullet are the best cases. It is the things domain controllers do under the covers that could really mess up your directory in unpredictable and potentially non-recoverable ways.
The fix?
Microsoft now detects USN rollback. All other domain controllers should refuse to replicate with that domain controller as an indication that you’ve messed up and you can go ahead and trash your snapshot restored domain controller and never do this again. The outcast DC will also turn off its own netlogon service and stop being useful in the environment. It is not perfect; it is possible that there are still orphan changes on the feral snapshot restored machine, but it is the safest thing they could do. It is also something that needs to be detected. Microsoft documented that USN rollback should be detected and replication stopped before divergence is created in most cases. It is also possible to toggle a registry key to let bad things happen despite all the warnings, but I won’t get into that here.
USN rollback is well documented in this knowledge base article:
Domain Controller Id:
The other important component is the domain controller invocation id. In short, this is how replication partners will get along with an AD recovery that is performed in a supported manner. You can see the invocation id in the replication metadata output for each domain controller, in this example - DC1:
repadmin /showreps DC1
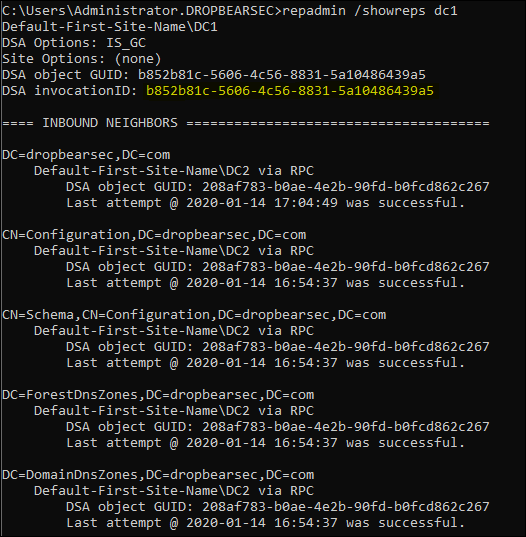
In the simplified USN example, the missing piece was the invocation id. When Active Directory is restored on a domain controller by using the APIs and methods that Microsoft has designed and tested, the invocation ID is correctly reset on the restored domain controller. Domain controllers in the forest receive notification of the invocation reset. Therefore, they adjust their high watermark values accordingly. Again using the previous example - the other domain controllers would have realized a restore has occurred, and would have replicated the 100 changes as normal.
Are there any Hacks?
Yeah. There are. But Microsoft is clear that the procedure is not supported and should be reserved for situations where there is no other alternative: restore a previous version of a virtual domain controller VHD. You shouldn’t build your strategy around this technique.
There’s a “DSA Previous Restore Count” key in the “HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\NTDS\Parameters” section of the domain controller registry that will turn your snapshot recovery mess into something will work. No guarantees and Microsoft go as far as calling this domain controller out of support going forward. If you had to do it in a pinch, id look to get things as stable as this hack allows, then decommission the feral machine, replacing it with a brand new one.
But what about the VM-Generation ID?
You got me. Most of the drama mentioned above has has improvements designed in to Windows since 2012, in cooperation with Hypervisor vendors. The VM generation Id was implemented in an effort to support clones and deal with snapshot restores in an even safer way.
“AD DS relies on the hypervisor platform to expose an identifier called VM-Generation ID to detect the snapshot restore of a virtual machine. AD DS initially stores the value of this identifier in its database (NTDS.DIT) during domain controller promotion. When an administrator restores the virtual machine from a previous snapshot, the current value of the VM-Generation ID from the virtual machine is compared against the value in the database. If the two values are different, the domain controller resets the Invocation ID and discards the RID pool, thereby preventing USN re-use or the potential creation of duplicate security-principals”. Microsoft’s virtualized domain controller architecture documentation covers the important details and caveats. Generally speaking, depending on the hypervisor, there is some protection there.
[For context, the attribute holding the id is: “msDS-GenerationID”]
So what you’re saying is…
The point I’m getting at: it seems foolish (to me) to rely on protections for snapshot style backup. If you have the chance to design your DR strategy from scratch, choose an option that leverages the backup API and you’ll have a fully supported backup that’s been tried and tested over the ~20 years active directory has been around. Even with the modern improvements, basing your strategy around alternate approaches seems less than ideal to me. (My recommendation would be to do both if my cloud or virtualization admins really had a thing for the snapshot functionality provided by the platform).
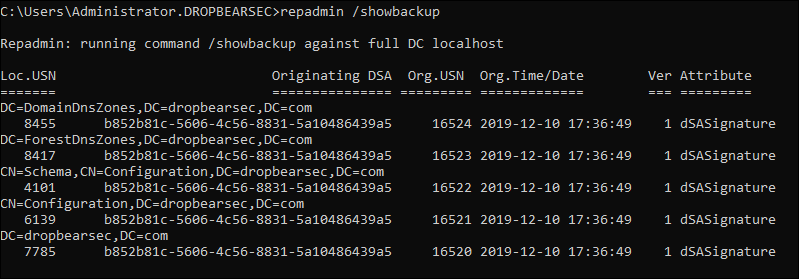
When you use the supported API, the directory service is in the loop all the way; and you can be confident it will be able to do the right things with any restore operation. For what its worth, you can actually see evidence of supported backups via repadmin /showbackup because the backup writes an attribute to each partition as it backs it up, indicating that the API was used correctly and a successful AD backup has occurred:
Thanks!