These are practical notes on Amazon Route 53 and DNS design. The focus is on the operational details that tend to matter during an incident: delegation, TTLs, health checks, alias records, routing policies, and how resolvers behave when the design is under stress.
2026 context: the core DNS and Route 53 routing concepts below are still useful. Before reusing any exact pricing or feature assumptions, check the current Route 53 documentation and pricing. DNS is simple until it is not: TTLs, negative caching, resolver behavior, health checks, and alias records can all make a clean diagram behave differently than expected during an outage.
Introduction
If you’re reading this, you probably know exactly what route 53 is, but just in case, Amazon describe Route 53 like this: “Amazon Route 53 is a highly available and scalable cloud Domain Name System (DNS) web service. It is designed to give developers and businesses an extremely reliable and cost effective way to route end users to Internet applications by translating names like www.example.com into the numeric IP addresses like 192.0.2.1 that computers use to connect to each other. Amazon Route 53 is fully compliant with IPv6 as well”
Route 53 does three related but distinct jobs:
- Domain registration, where Route 53 can act as the registrar for a domain.
- Authoritative DNS hosting, where hosted zones contain the records resolvers query.
- DNS-aware traffic steering, where routing policies and health checks influence the answers Route 53 returns.
Keeping those roles separate helps when troubleshooting. A registrar problem, delegation problem, hosted-zone record problem, and health-check problem can all look like “DNS is broken” from far away.
DNS Refresher
There are many analogies around phonebooks for domain names to IP addresses, and that explanation is valid, and works well for general discussion. But its important for infrastructure engineers to remember that more accurately: DNS is a database of domain name resources. IP addresses are a resource for sure, but they are not the only resource type in a DNS zone. IPv4 Addresses are generally the A but the resource could just as easily be an IPv6 address, or a txt record:
| Domain Name | Resource Type | Resource Data |
|---|---|---|
| chadduffey.com | A (IPv4 Address) | 10.10.10.10 |
| facebook.com | AAAA (IPv6) | 2a03:2880:f101:83:face:b00c:0:25de |
| microsoft.com | TXT (Text) | “facebook-domain-verification=m54hfzczreqq2z1pf99y2p0kpwwpkv” |
DNS is scaled by distributing zones between name servers via delegation. As a very high level example: for chadduffey.com., the chadduffey zone information is stored on separate DNS servers from the com zone, which is again separate from the root “.” zone. The root holds records indicating where the com zone servers can be found. The com servers hold information about where to find the chadduffey zone. A resolver attempting to find a resource for the chadduffey.com. domain could start with the root server, which would send the resolver to the com server, the com server would send the resolver to the chadduffey name servers, and the resolver would query those name servers for the resource information. This is recursive resolution.
Domain Name Registration
Working with jmpesp.xyz as my example:
- Registrar (godaddy) confirms availability with the company managing the.xyz Top Level Domain (TLD) (For context, XYZ.COM and CentralNic manage this one)
- Registrar creates registration with company managing the .xyz TLD
- Registrar tells the company managing the .xyz the name servers that should be authoritative for the domain I am registering. (usually starts as the name servers of the registrar)
- .xyz registrar creates name server resource records (at least two) pointing to the godaddy name servers; from there, as an admin I could go ahead and modify things via the godaddy console.
Route 53 Public Hosted Zones (and Reusable Delegation Set’s)
- Route 53 will use four different name servers each time you create a new public zone.
- This is fine for a single domain setup, but for larger services, a feature called a reusable delegation set is available.
- PowerShell only. “$delegationset = New-R53ReusableDelegationSet -CallerReference (Get-Random)”

- This set of nameservers can be associated with up to 100 zones.
- Get the id: “$dsid = $delegationset.DelegationSet.Id”
- Set the zonename: “$zonename = “jmpesp.xyz.”
- Create the zone: “$zone = New-R53HostedZone -Name $zonename -DelegationSetId $dsid -CallerReference (Get-Random)”
- Optionally, view zone information “$zone.HostedZone” (or nameservers with “$zone.DelegationSet.NameServers”)
Actually, while we are here, don’t forget that when you are messing with public DNS it is possible that the queries are cached both on your local client (a windows machine in my case), and possibly on your DNS resolver for the duration of the existing TTL value for the zone. For the windows machine, “ipconfig /flushdns” might help you to speed things up.
Another important point is the negative caching TTL (when you query for something that doesn’t exist and rather than having the client keep asking, the negative ttl record just says - nope, already tried, doesn’t exist) which is defined and modified if needed on the SOA:
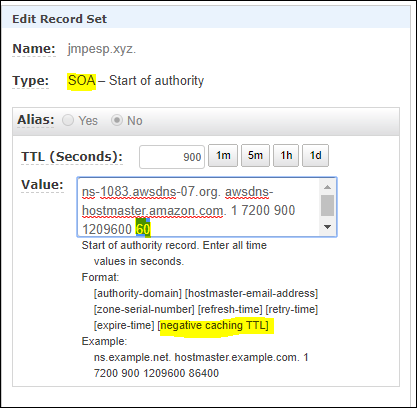
CNAME v Alias: CNAME is the DNS record type; alias is a Route 53 feature that lets AWS answer with the relevant target values for supported AWS resources.
APEX record: A record at the root of the zone itself, like jmpesp.xyz.
Why call out that first distinction for alias v CNAME (sounds like just terminology)? Because there are alias records that are not CNAMEs. Like the example below where the apex is an alias record despite being an A type resource. This matters because standard DNS does not allow a CNAME at the zone apex, but Route 53 alias records can solve that AWS-resource use case cleanly.
What about wildcard records? anything.jmpesp.xyz -> (alias) -> www.jmpesp.xyz
Health Checks (for DNS load balancing):
HTTP, HTTPS or TCP (can do more than just web services)
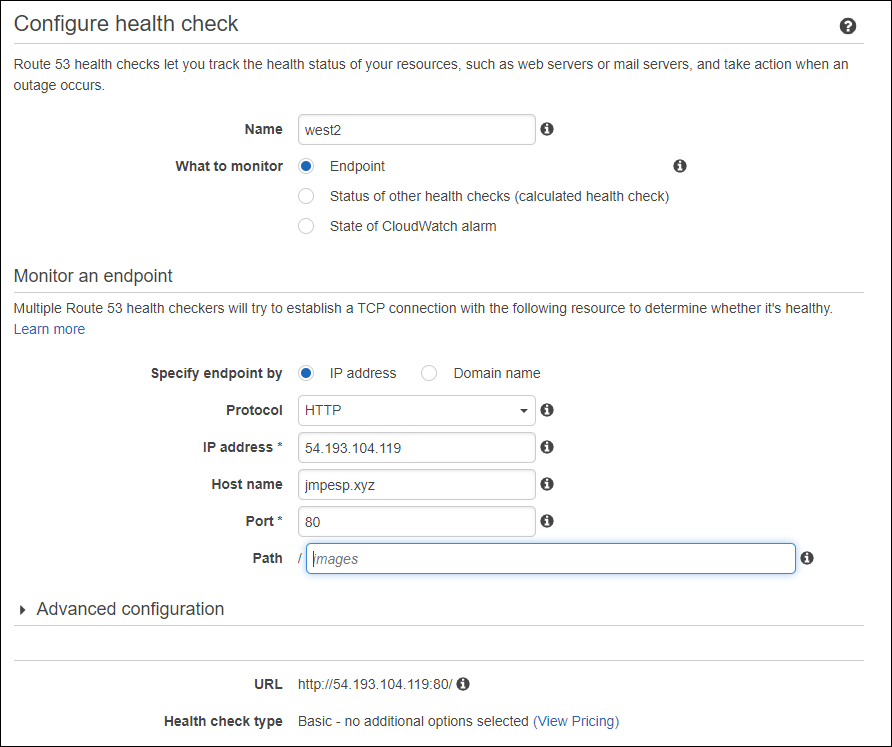
We should see the Amazon health checkers retrieving the test page that we configured in the health check.

Some tips:
- Health checks are typically HTTP requests. If the instance is under powered this will have a non zero effect on the service.
- You could consider removing some of the health checkers to further reduce the load. (By default health checkers from most regions are included so you have multiple servers checking in on your web server every X seconds)
- You could also reduce the checking interval.
- Make sure the health endpoint tests something meaningful. A static “OK” page might prove the web server is alive while the real application is broken.
- Think about failure modes before lowering TTLs everywhere. Low TTLs can help failover, but clients and recursive resolvers do not always behave exactly the way your whiteboard says they will.
Which routing policy should I use?
As a rough decision guide:
- Use simple routing when there is one answer and you do not need health-aware steering.
- Use failover routing for active/passive designs where one target should only be used when the primary is unhealthy.
- Use weighted routing for gradual migrations, canaries, or deliberate traffic splits.
- Use latency routing when users should generally land on the lowest-latency regional endpoint.
- Use geolocation/geoproximity when business, compliance, or content requirements depend on geography rather than pure latency.
- Use multivalue answer routing when you want DNS to return multiple healthy IPs and let the client choose.
Route 53 can chain these patterns, but each layer makes incident response harder. Draw the intended decision tree, include TTLs and health checks in the drawing, and test failure before calling the design complete.
Failover Records
Once we have the health check, we can associate it with a alias target to be used for failover.
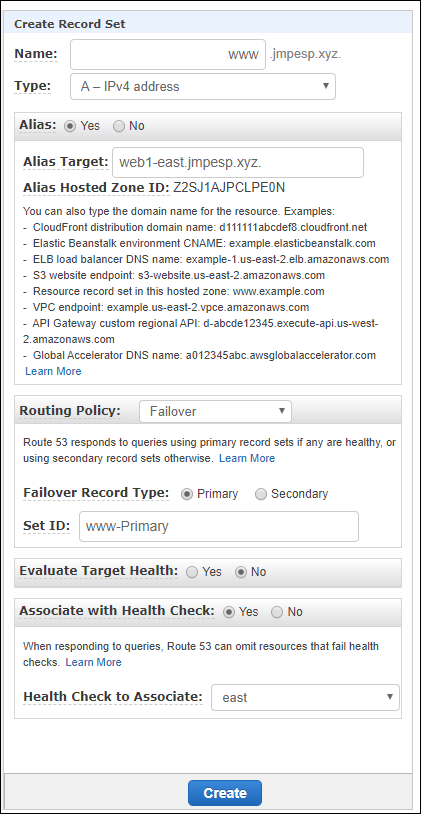
For the simple example, the resulting records will look like this:

It gets interesting when you start to chain these together. It is recommended to carefully draw out the desired configuration before messing in the Route 53 DNS manager but as an example, we could create two east.jmpesp.xyz records. Then, create the same in a West region (west.jmpesp.xyz). Then, we could set up www.jmpesp.xyz to point to the geography alias records, then have route 53 “evaluate target health”, but not rely on a health check for the new alias records. We’d get redundancy spread across all geographies.
We can also do something pretty interesting for when all of the failovers are down… We can configure a S3 bucket with a static webpage that lets our users know that we are in a bit of trouble gracefully. We can configure a failover record with the S3 bucket as the target. To make this work, the bucket name must match the site that the user was trying to hit - for example “www.jmpesp.xyz”. Configure (upload) the basic web page to the bucket, make it public. Then, on the failover record in route 53 we would point the failover record to s3-website-use-west-1.amazonaws.com. Its the host header in the HTTP request that is going to help this request get to the right bucket (assuming all other hosts are down).
Distributing Traffic with Weighted Records
Instead of failover (active and passive) we have “weighted” as the alias type.
Weighted records are always active unlike the active/passive failover records. If we have multiple records with the same weight it can be random distribution of the load. Adjusting the weight of records allows you to decide which servers serve most content.
The configuration looks very similar to the failover records. The difference once configured is the weight shown highlighted below (health check association also shown highlighted)

A handy way to check that different records are being distributed (remember the 25% weight) is to use https://dnspropagation.net/ and entering the domain. Notice below that different DNS servers around the globe were given different answers for www.jmpesp.xyz? This represents the four weighted records we configured above.
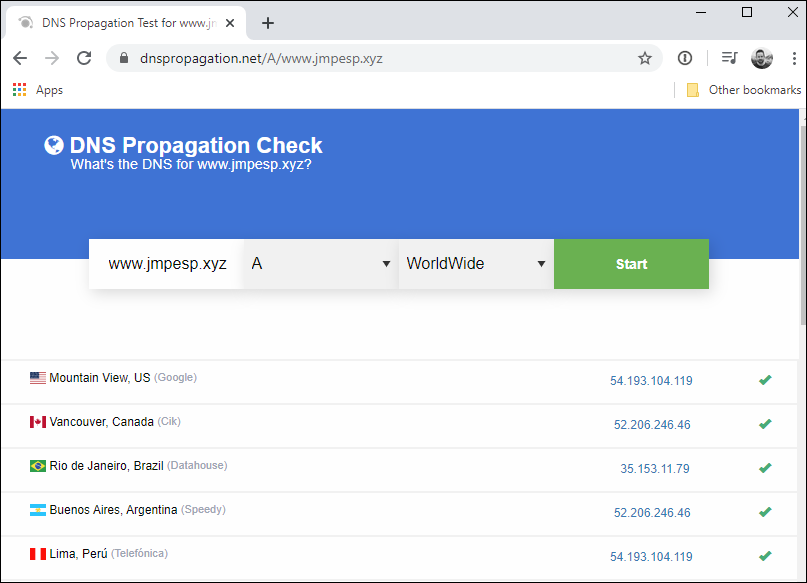
Remember, that we’ve configured equal weight distribution here but its totally possible to distribute the load somewhat by adjusting the weight distribution assigned to each record. Maybe we want the West coast servers to serve 80% of traffic, but we allow the East coast to serve up 20% of the time or something similar.
What about health checks? Why are they on the weighted records? Well, its pretty cool. Route 53 won’t route traffic to a ‘down’ machine. It changes the weight to zero under the covers, adjusting upwards the weight of all other records (in the background, not in the UI).
If all machines are down? Route 53 treats them all as equal… remember that they would all be zero under the covers, so they have equal weight and all the equally down servers would be returned.
It is possible to get creative and combine failover and weighted in a chain. This might be a good approach for that backup S3 bucket “site down” page.
Geo-location records
Geo-location records allow us to route traffic based on where the request originated.
However, be careful. This is the location of the clients DNS server that is doing the recursive resolution of the record.
Also be careful that the most specific record is chosen, not necessarily the ‘closest’.
And, make sure that a ‘default’ location record is also specified if you want world wide access to the service.
As an example - I might configure my web1-west server to serve all USA like this:
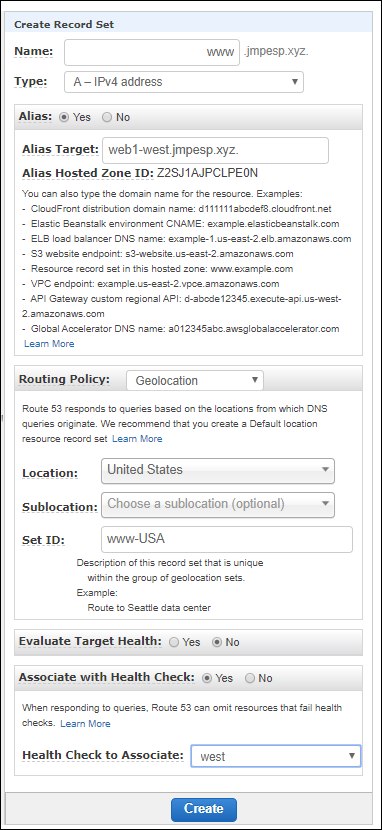
But for my heavy users in Seattle, I might choose a separate server: web2-west and use geolocation to override with a more specific record:
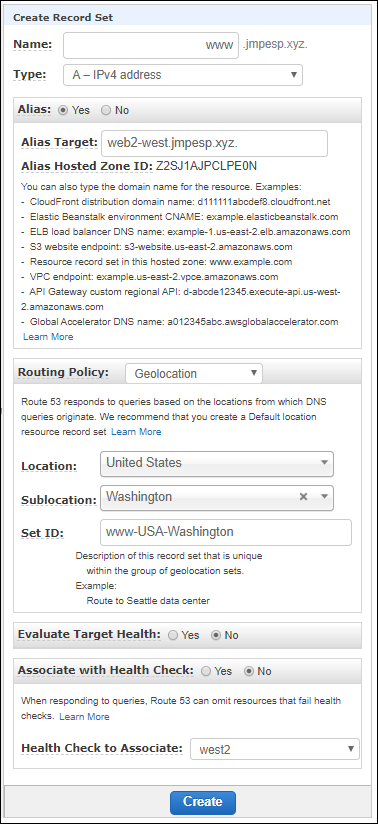
I’d then configure a catch all (or two) to return to clients that are neither Washington or broader USA.

Latency Records
We can route to the server with the lowest latency based on regions.
It is somewhat unpredictable with testing using dnspropogation.net site because latency will change minute by minute but this can be a good thing.
Traffic Flow Policies
Easy to configure.
Two components: 1) traffic flow visual editor (drag and drop, generates policy) 2) Policy records
Policy records were expensive when I took these notes. Check current Route 53 pricing before using Traffic Flow in anger.
Here’s what the editor looks like (the thing that creates JSON for us):
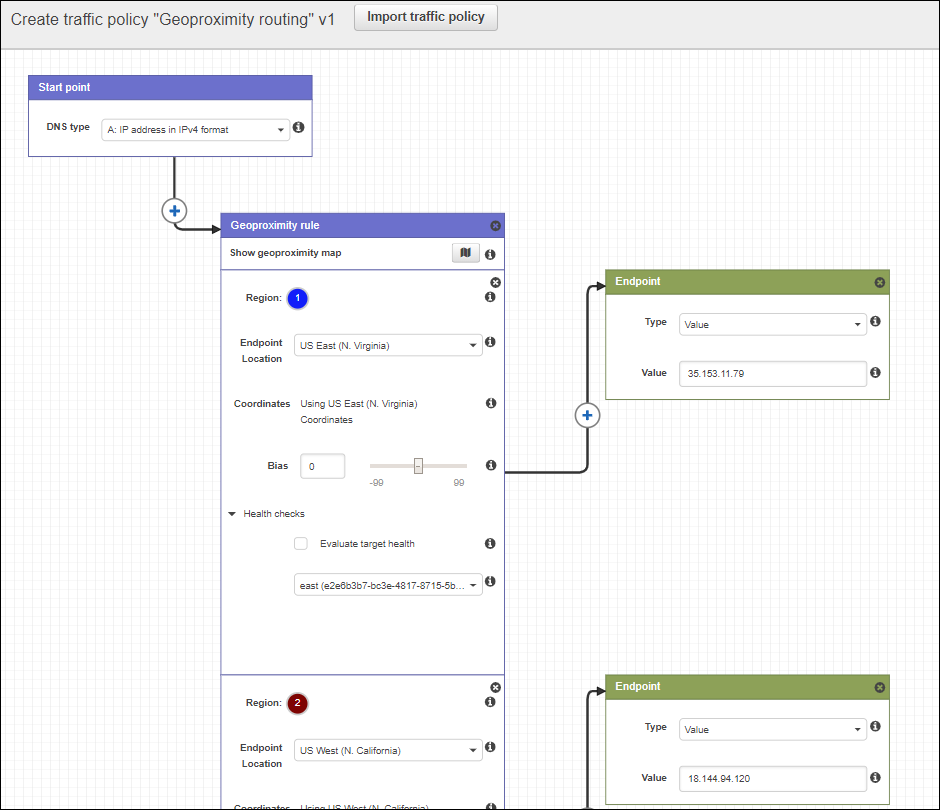
Load Balancing with Multi-value answer records
The ability to send back more than one IP address is an answer.
Client can decide which to use.
If client can’t connect to the first, they might have the smarts to retry with the second.
We can assign health checks to multi-value records, which is useful because the route 53 service can pull records out that have failed their health checks.
The benefit of the this over a simple multivalued resource record is that the route 53 server is pulling out the down servers in responses. That is pretty good, but do remember that if all servers fail route 53 would go back to returning all records to the client.
Private Hosted Zones
Resolvable only by resources in your VPC associated with the zone.
Can support split brain DNS in this way, having an internal jmpesp.xyz for our VPC, then hosting the external jmpesp.xyz outside with completely different records.
To create, we choose “created hosted zone” as usual. But there is a type for “private hosted zone for amazon VPC”. In the settings we tell route 53 which VPC to assign the service to.
If you click “hosted zones” in the AWS console you’ll see either “private” or “public” for each zone.
We can also associate a private zone with additional VPC’s. If you re-open the zone there’s a VPC section, choosing a second VPC reveals a “associate new VPC” button.
Private hosted zones remove the need for hard-coded IP for the internal working of services inside private VPCs.