This post captures lessons learned while testing and tuning Defender Exploit Protection. The mistakes are useful because exploit mitigations are easy to enable in a lab and much harder to operate safely across a mixed application estate.
They’re not meant to be interpreted as criticisms of the product; just thing’s I wish I’d realized earlier in the process.
Summary
Mistakes:
- Misunderstanding the behavior of the settings export (from a reference machine)
- Misunderstanding the behavior of the Group Policy client side extension.
- Assuming that there was no harm in ‘audit only’ settings
- Scoping the project too broadly at first
Detail
1. Misunderstanding the behavior of the settings export (from a reference machine)
The general advice for Exploit Guard deployment in an enterprise is to configure a reference machine, then export the settings for distribution via one of the supported mechanisms. For us, it is Group Policy.
You can export via the UI, or with PowerShell. Something like Get-ProcessMitigation -RegistryConfigFilePath c:\temp\EG.xml will get you moving in the right direction.
Issues:
- The export behavior does not create a file detailing all the settings on the reference machine.
- The export writes out deviations from what is considered the default. You can see those as “Use Default (On)” or “Use Default (Off)” in the UI.
- The default settings might be slightly different depending on the version of Windows being used as a reference machine.
Originally, our assumptions were slightly different than the behavior described above.
We originally believed we could rely on the exported .xml to be a reference of the configuration that was enforced on all of our machines in the fleet.
We maintained the .xml file in a public section of our internal information security wiki and had assumed we could point support teams to that file as the source of truth for how our machines were configured.
Example:
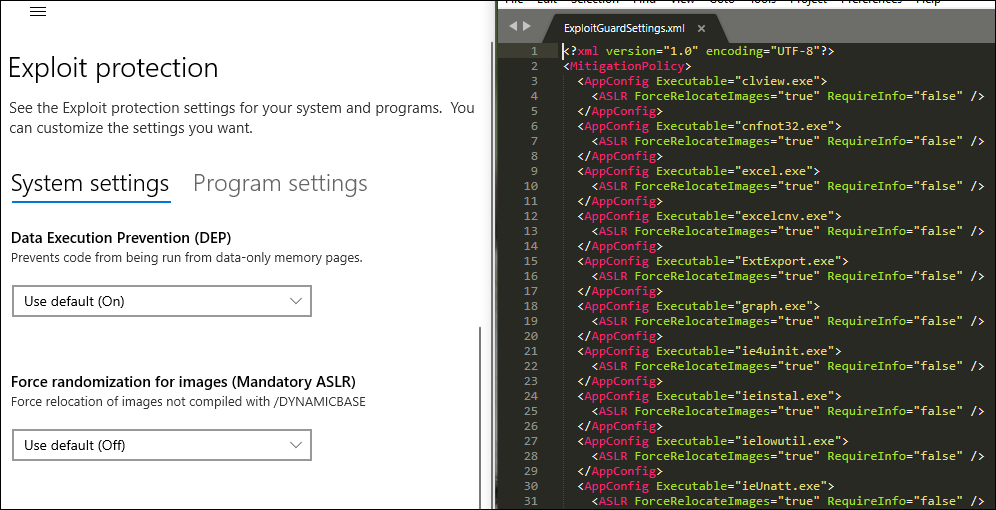
In the image below you can see that DEP and ASLR are set to use the system defaults on the left side of the image.
On the right is the exported XML.
We’d expect the system wide configuration settings to be at the top but there are none configured for fleet wide configuration. Instead, clients receive defaults supplied by Microsoft in version updates.
Recommendation:
- Understand that the export process is not capturing all the settings on the reference machine. Just those that are not default for the version of windows you’re using.
- Set things explicitly on the reference machine to improve predictability.
Useful reference:
- Gunnar Haslinger maintains a repository which attempts to capture the defaults for various Windows versions.
2. Misunderstanding the behavior of the Group Policy client side extension.
Issue:
- We believed that when configuring a set of rules via GPO we could update the rules file and have it applied to all machines. This appears to be wrong in two ways.
- One: The client side extension does not seem predictably responsive to changes in the xml. Instead, we’ve found that clients are more responsive to a new (name) xml such as
exploit-guard-1.1.xmlthenexploit-guard-1.2.xmletc when changes are made. - Two: The settings are not applied to clients as “here’s the rules you should configure to replace what you have”, instead they appear to be an aggregate of what the client has and the rules being pushed. This can be confusing from an enterprise perspective. The rules can also be modified on the client side and not predictably refreshed by the group policy (point one from this section).
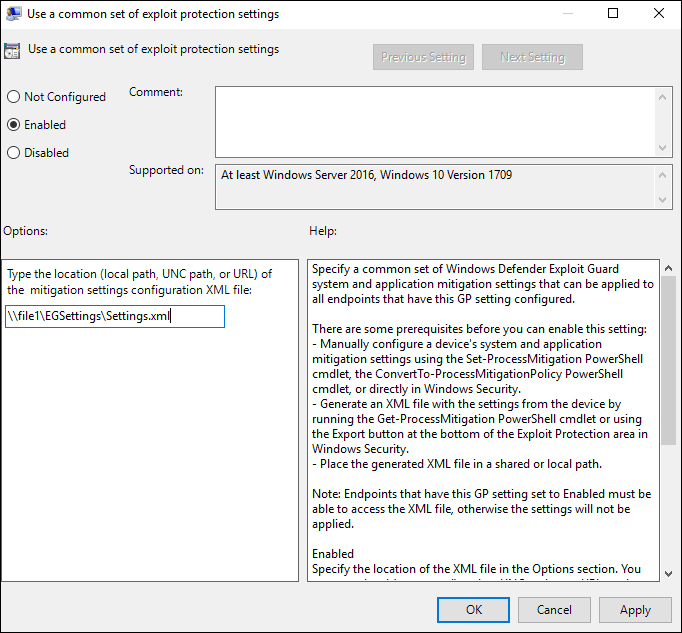
Issue 1 for the GPO behavior is simply this setting under “Windows components > Windows Defender Exploit Guard > Exploit protection”:
Recommendation:
- Instead of changing the file itself, change the GPO each time to point to a new file. Maintain the history of settings in the share. Something like:
exploit-guard-1.1.xmlthenexploit-guard-1.2.xmletc.
Issue 2 for the GPO behavior is just a heads up. I don’t believe a mode exists where you can say “Here’s the corporate policy, apply this (and throw away what you had)”. This behavior makes it more difficult to get the environment into a predictable state.
3. Assuming that there was no harm in ‘audit only’ settings
This was a big one (for us). I’ll put my hand up and say “we messed up” on this and we are lucky to be working in an environment where the infrastructure could absorb our mistake over a short period of time.
Here’s a summary of how it went wrong:
- In our corporate settings we configured Arbitrary Code Guard in Audit Only mode for most of our corporate applications.
- We are heavy users of Windows Event Forwarding.
- We didn’t pay close attention to the event’s right away.
- We considered audit only changes as being low risk.
Arbitrary code guard is excellent for the right type of application. It’ll prevent the introduction of non-image-backed executable code and should prevent code pages from being modified in memory. The problem is, that some applications are never going to work with that configuration. Slack stands out as a bad choice for this control. As James Forshaw put it: “Slack is Electron based which would be using V8 JIT for Javascript, JIT doesn’t play nice with ACG”. Slack isn’t the only JIT application in our fleet, we had a couple that ACG really wasn’t designed for.
But what’s the big deal if it is only in audit mode?
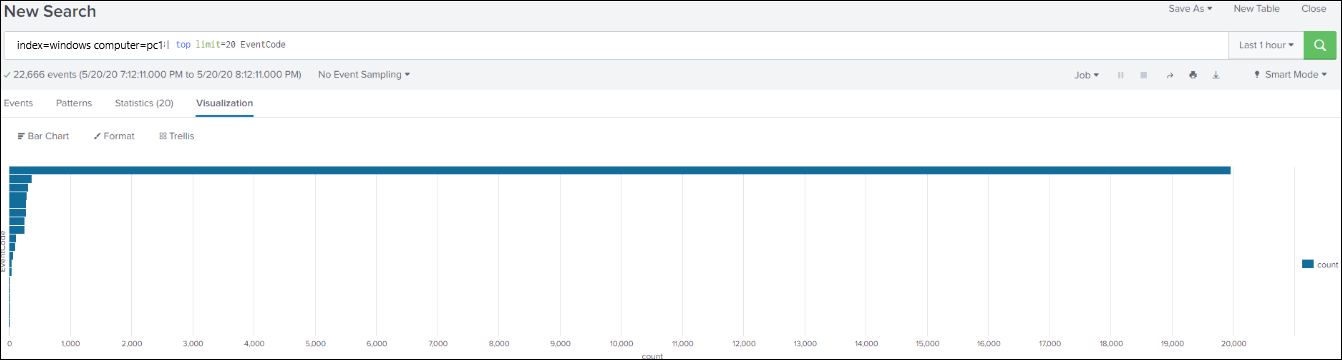
It is difficult to see in the image (apologies, it is from my incident notes), but the longest bar is arbitrary code guard events. The graph is showing that we were getting roughly 20,000 events per hour from Arbitrary Code Guard audit-only events. For a single machine.
The events say: Message=Process {details} would have been blocked from generating dynamic code.
If we only had 100 machines, that’d be 2,000,000 events per hour being event forwarded into our logging system. (We have many more than 100 machines).
The impact of this misconfiguration was noted:
- On endpoints, both as significant CPU consumption and moderate Disk I/O.
- On WEF infrastructure servers as significant CPU / Network and Disk I/O.
- On our event storage volume capacity.
The lesson here isn’t that arbitrary code guard isn’t right for JIT applications, we should have known that from our research.
The lesson was the sheer volume of events that would be generated in the normal operation of an application not suited to this control.
The forehead slap was not carefully measuring this impact on a reference machine before deployment. Because, you know - audit only mode couldn’t really cause issues for our users.
Recommendation:
- Be careful with audit only settings. The volume of events might be higher than you expect.
4. Scoping the project too broadly at first
We attempted to cover as many corporate applications as we could with Exploit Guard as our v1.0. I think that’s the wrong approach. I think being previous EMET users made us a little cocky.
In my opinion: what we should have done instead, was audit the top 20 applications used in our fleet.
From there, consider the application types, use cases, vendor reputation etc and identify maybe 5 - 10 that would get genuine value from the extra protection offered by exploit guard.
Applications written in non memory safe languages; or applications that accept input either from the network, or as a file > open type arrangement are good candidates.
That would provide a solid v1.0 to deploy and ensure stability over a week or two.
From there, continue to go down the list of corporate applications and identify others that could benefit from EG controls. Deploy settings.xml revisions after testing each new application.
Using this approach we could notify the help-desk each time: “Exploit Guard Revision 1.2 is going out today - it impacts ApplicationX and ApplicationY. Please let us know if you receive any tickets”.
We could also monitor infrastructure and endpoint performance relative to the change. Then repeat/iterate till we have good cover for all applications we might care about in this context.
Another approach, rather than auditing applications might be to consider the STIG recommendations for common corporate applications.
The value of taking the STIG route is that there’s a good chance the applications have been tested for compatibility with the recommended settings.
Here’s just a few examples:
For context: The full Windows 10 STIG covering much more than exploit guard is here.
In any case, our mistake here was treating Exploit Guard deployment as a short term project, and planning around an aggressive time-frame. I’ve come to believe that it is better to get the small number of system wide settings and a few applications completely covered first. Then to iterate on that base over time as a routine security team operation.
Recommendation:
- Keep your Exploit Guard deployment scoped to a handful of applications you understand well at first. Iterate from there.
Other
We published a blog post covering our experiences with Exploit Guard almost a year ago. You can still find the original post here. At the time Matt Graeber was working with us as part of our SpecterOps partnership and we also published a stack of his work regarding Exploit Guard for detection and alerting on Github.
For reference, there is a previous post testing exploit guard against buffer overflow here. And another testing against image loads (process injection) here.